

购物车
 您的购物车当前为空
您的购物车当前为空


 很棒
很棒近年来肥胖已成为全球普遍的公共健康问题,肥胖是一种由多种因素(遗传、饮食习惯、生活方式和环境)相互作用引起的复杂的疾病,通常伴随着胰岛素抵抗、氧化应激和炎症标志物表达增加,导致体内脂肪含量增加。肥胖容易引起糖尿病,高血压,动脉硬化等多种代谢紊乱性疾病。
创建该库的主要目标是识别通过不同于GLP1R激动机制发挥作用的新型潜在抗肥胖化合物。该方法旨在通过探索涉及体重调节的替代分子靶点和途径,应对日益严重的肥胖流行病。
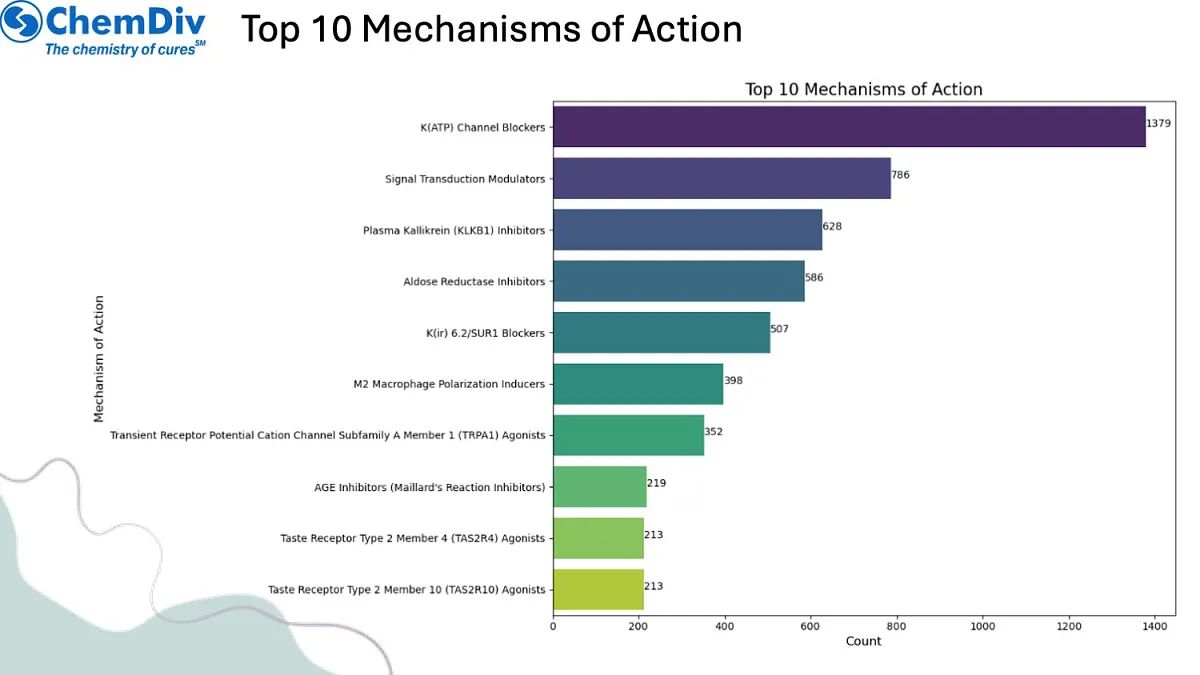
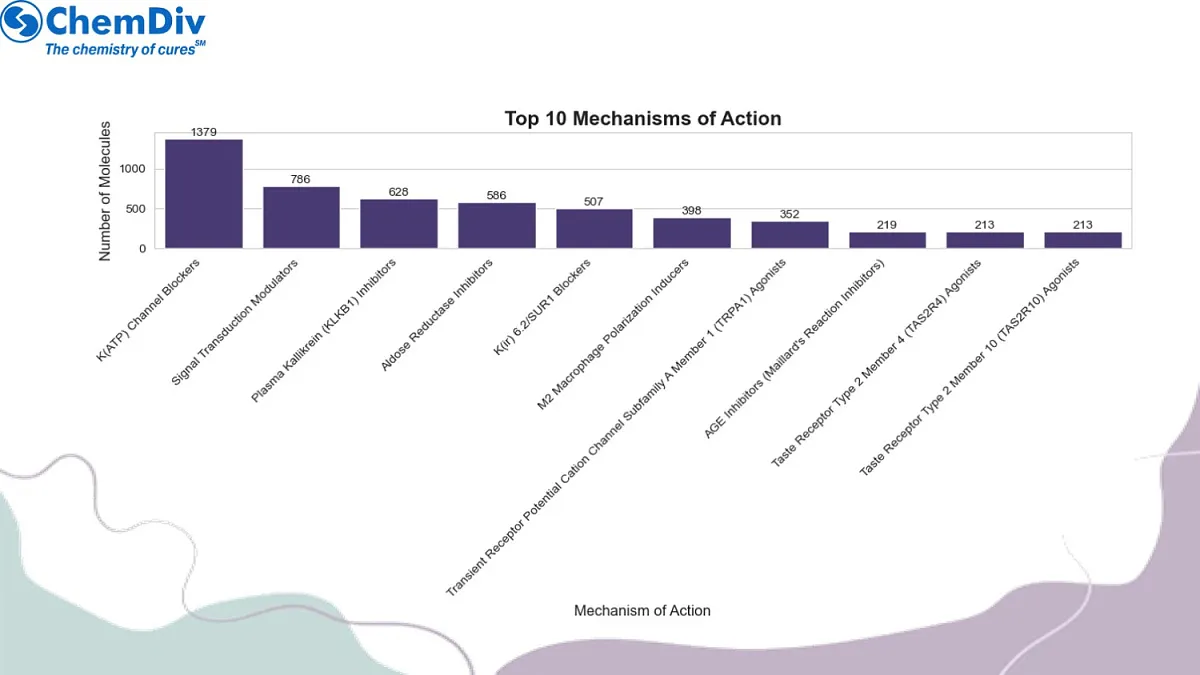
当前的肥胖靶点包括参与食欲调节、能量消耗和脂质代谢的各种受体和酶。通过排除针对GLP1R的化合物,该库专注于其他有前景的靶点,如MC4R、SGLT2和各种脂肪酶抑制剂。这一策略可能发现新的治疗方法,与现有治疗相比,副作用更少或疗效更佳。
该库的最终目标是为肥胖治疗领域的进一步计算机筛选、体外测试和潜在药物发现工作提供宝贵资源,可能揭示新的作用机制和更有效的疗法,以应对这一复杂的代谢紊乱。
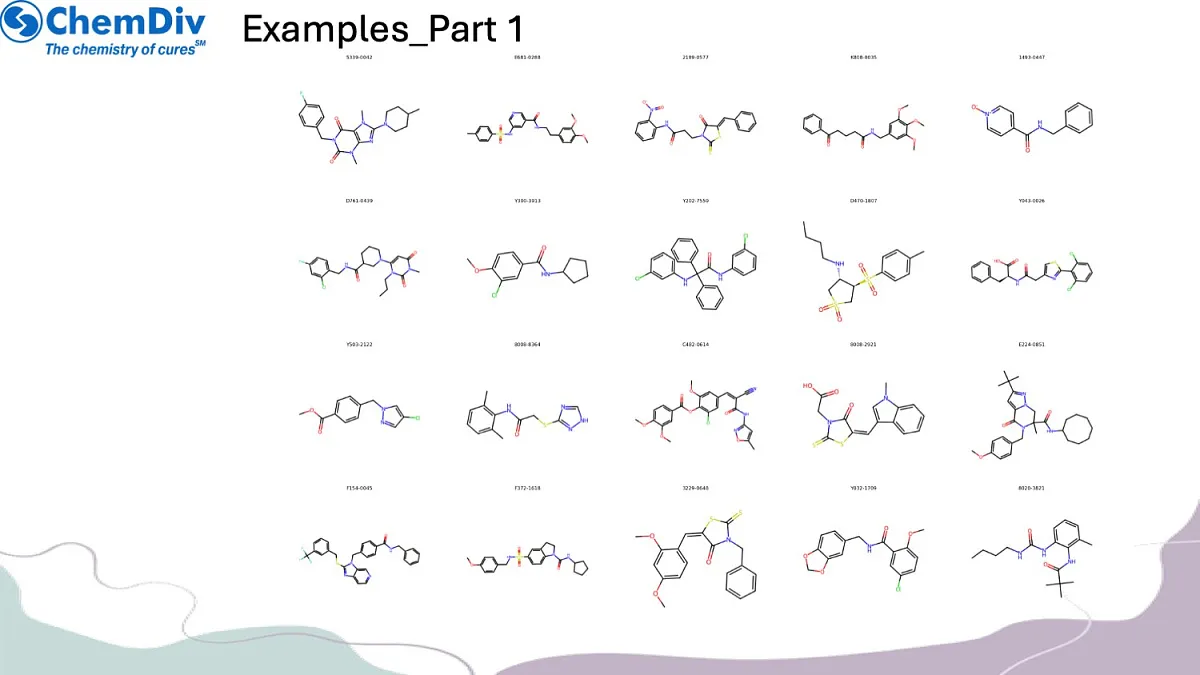
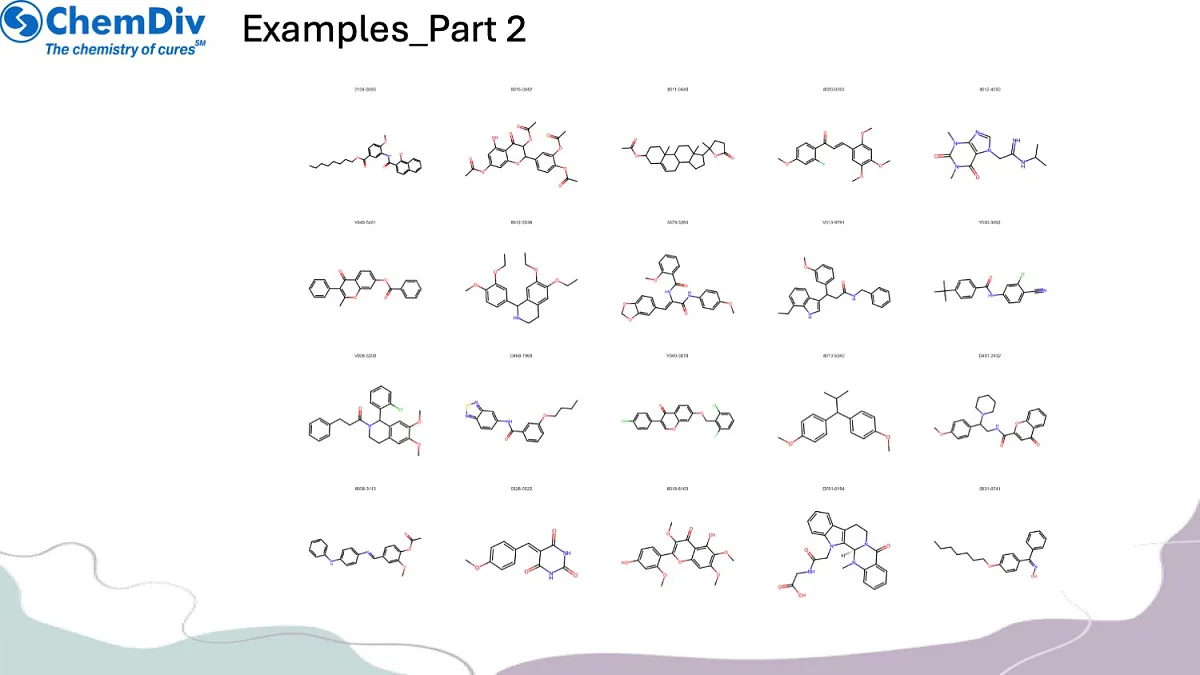
抗肥胖化合物库包含11076个筛选化合物。
本研究利用ChEMBL、Google Patents、SciFinder及科睿唯安Cortellis药物研发情报等权威数据库,对肥胖治疗相关分子进行了系统性检索。具体流程如下:
参考化合物识别:从数据库中提取具有已知或潜在抗肥胖活性的多样化化合物,重点收录已注册或处于肥胖治疗临床试验阶段的分子。
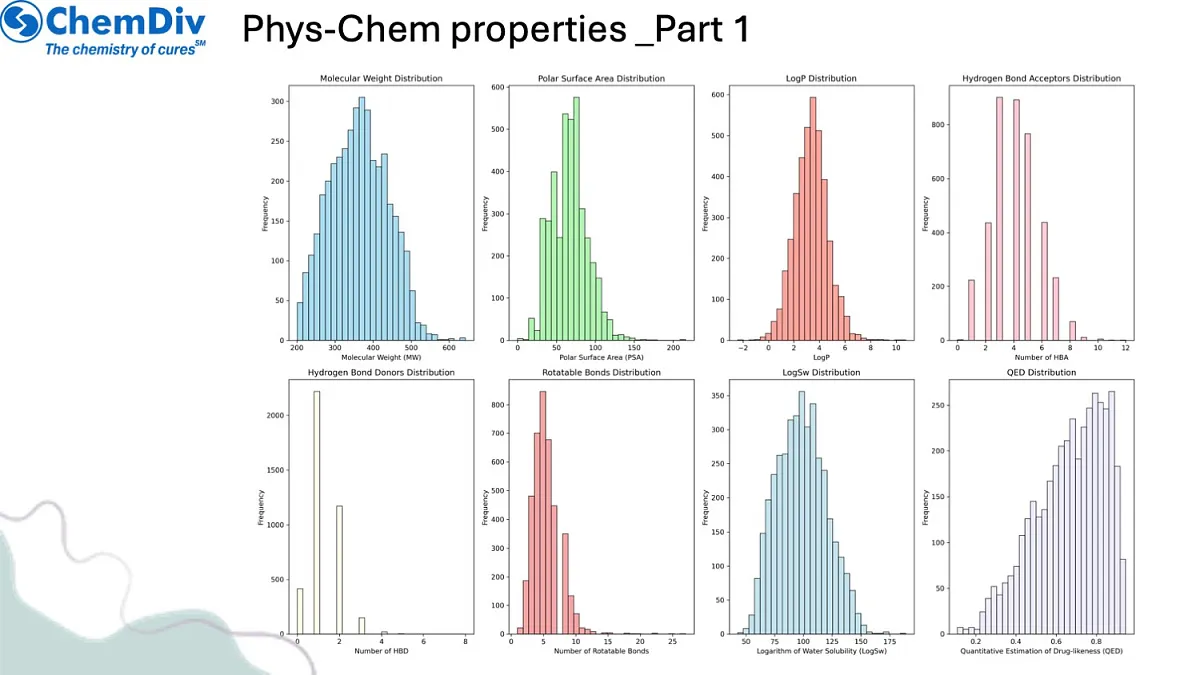
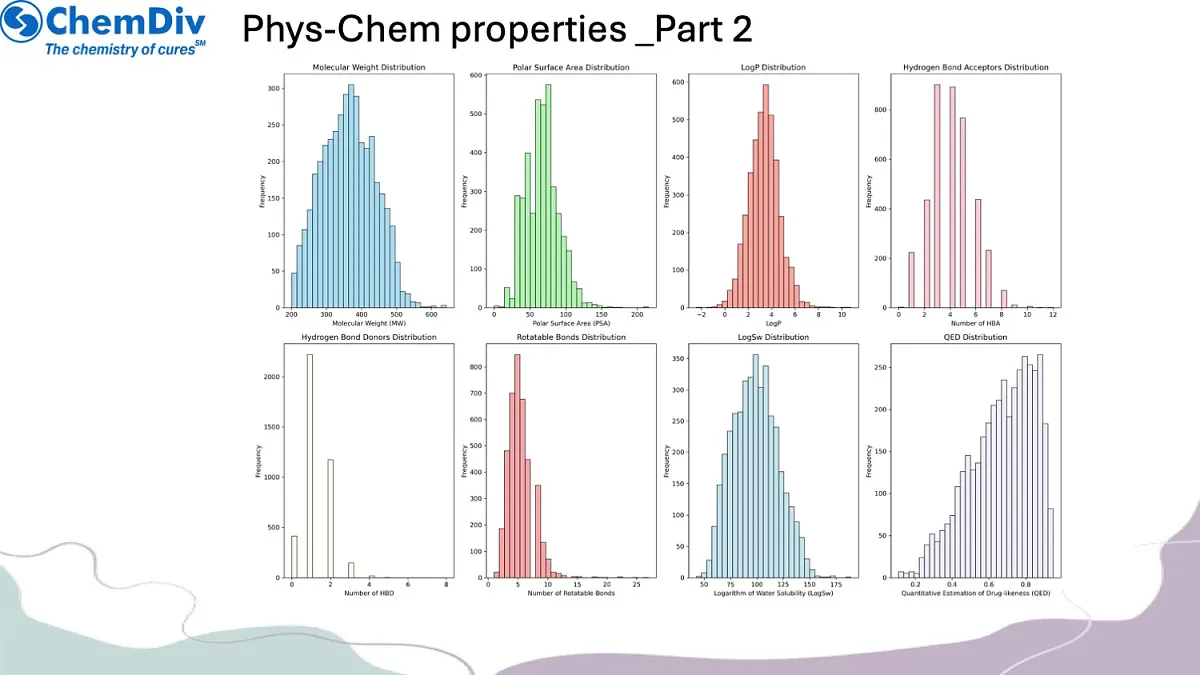
结构特征分析:对鉴定化合物的化学结构进行多维度解析,包括分子描述符(如分子量、脂水分配系数logP)、二维拓扑特征(如连接性指数)及三维构象属性(如形状指数),建立各化合物的综合结构图谱。
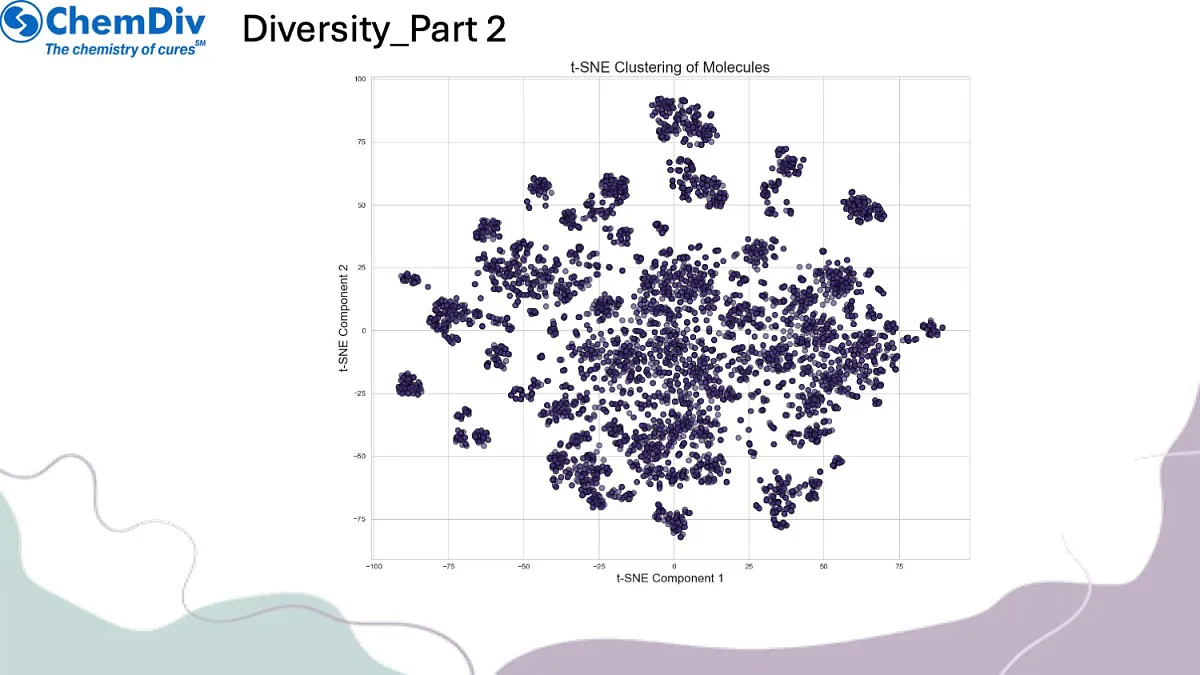
相似性评估:运用先进化学信息学工具,通过二维指纹图谱塔尼莫托系数与三维形状相似性度量等多重指标,评估已知抗肥胖化合物与大型分子数据库的结构相似性,识别结构相关分子。
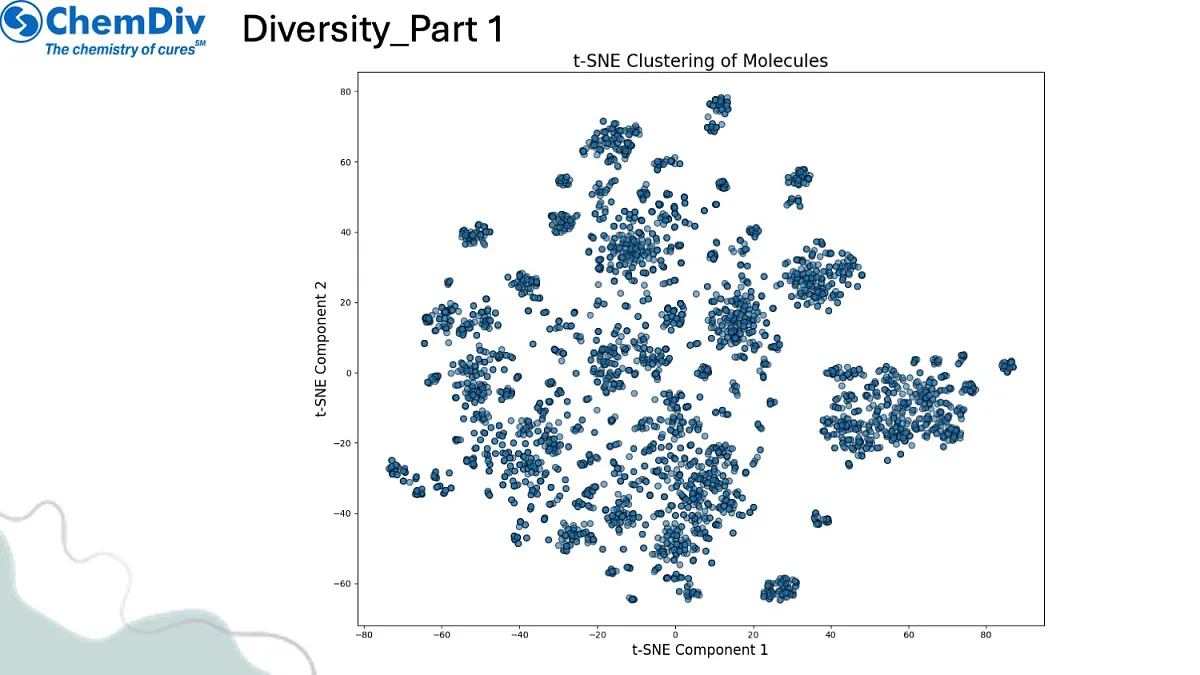
分子库构建:基于与已知活性分子的结构相似性,创建靶向抗肥胖化合物的聚焦分子库。值得关注的是,本研究策略性排除了GLP1R靶向分子,以确保作用机制多样性并探索新型治疗路径。最终分子库在满足预设相似性阈值的同时,保持了结构多样性特征。
研究目标:本分子库旨在发掘非GLP1R激动作用机制的新型抗肥胖化合物,通过探索体重调节的替代分子靶点与通路,应对日益严峻的肥胖流行趋势。当前肥胖治疗靶点涵盖食欲调节、能量代谢和脂质代谢相关多种受体与酶类。通过排除GLP1R靶向化合物,本库聚焦于MC4R(黑皮质素4受体)、SGLT2(钠-葡萄糖协同转运蛋白2)及多种脂肪酶抑制剂等其他潜力靶点。该策略有望发现较现有疗法副作用更少或疗效更优的新型治疗路径。
应用前景:本分子库旨在为肥胖治疗领域的计算机虚拟筛选、体外实验测试及药物研发提供重要资源,有望针对这一复杂代谢性疾病揭示全新作用机制与更高效治疗方案。




 嗨!有任何问题?点我咨询
嗨!有任何问题?点我咨询
版权所有©2015-2026 TargetMol Chemicals Inc.保留所有权利.
沪ICP备20019793号-4 | 沪公网安备 31010602006700号 | 沪(静)应急管危经许[2024]203441
| 沪(静)应急管危经许[2024]203441